

Polish project White-tailed Eagle AI It's increasingly appearing in conversations about large language models—not just as a curiosity "made in Poland," but as a viable alternative for specific applications. By 2026, Bielik already has several mature versions, its own benchmarks, and a growing number of implementations, which naturally raises the question: how does it compare to global giants like ChatGPT, Claude, or Gemini?
This article is neither an uncritical eulogy nor an attempt to prove that "Polish AI is the best in the world." Instead, we look at the facts—technical reports, research results, and real-world use cases—to see, where the White-tailed Eagle is actually doing very well, where it has limitations and when his choice makes more sense than reaching for commercial models from overseas.

What has changed in Bielik in recent months?
In the second half of 2025 and at the turn of the year (end of 2025 - January 2026) changes took place around Bielik, which are turning it into more and more of a "Polish LLM for testing" a mature family of models and tools – with a clear direction: good Polish, reasonable efficiency and real usability in implementations.
The most important changes are:
• Debut of Bielik-11B v3.0 Instruct – a publicly available instructional version (Instruct), described as the next step in the v2 line. The model card highlights, among other things, training using HPC resources (Athena/Helios) and a strong emphasis on multilingual quality in Europe (while maintaining priority for Polish).
• Establishing the "small" Bielik v3 (1.5B and 4.5B) as a fully-fledged project branch – along with the v3 Small technical report. This is important because it's not a "stripped-down version of the large model," but a conscious approach: better efficiency in Polish thanks to, among other things, a proprietary tokenizer and training solutions that are designed to improve quality without inflating parameters.
• Better availability for running locally (self-hosted) – next to the publications on Hugging Face, you can also see distribution channels typical of the „local LLM” world, e.g. packages for Ollama (which really lowers the entry threshold for testing on your own equipment).
• More „external” verification and pressure to standardize tests – public applications for evaluation in initiatives such as EuroEval appear (this is a signal that the community wants to compare models in a structured way, and not just based on impressions).
In practice, this means that "Bielik in 2026" is no longer one model, but ecosystem: from small versions (cheaper to run), through medium/larger instructional variants, to an increasingly mature approach to comparing results and distribution.

How to even measure "how good a model is" - criteria that make sense
Comparing language models can easily be reduced to one question: which one is the best? The problem is that in practice there is no single universal measure of "AI quality"„. Whether a particular model is "good" depends on this what it is to be used for, in what language and under what conditions. Therefore, before comparing Bielik with global giants, it's worth sorting out the criteria that actually matter.
Benchmarks – useful, but not sufficient
Benchmarks are standardized tests that assess, among other things, text comprehension, reasoning, and response generation. They are necessary because they allow for comparison of models under similar conditions, but they have significant limitations. They often examine narrow range of skills, are prone to "learning to the test" and rarely reflect real working conditions, e.g. with company documents or unstructured data.
Therefore, a high benchmark score does not always mean that the model will be suitable for everyday use – especially outside of English.
Language and cultural context
One of the most frequently overlooked criteria is quality of work in a specific language. Models trained primarily on English-language data may achieve excellent results globally, but in practice may perform worse with:
• complex inflection,
• idioms,
• legal or official language,
• local cultural context.
In this sense, a model that is "weaker" in terms of parameters, but trained with a given language in mind, is simply more useful in specific tasks.
Response stability and hallucinations
More and more attention is paid to this, how the model behaves when it doesn't know the answer. From the perspective of a business or administrative user, it is important not only Whether the model will respond, but How this will do:
• whether it clearly signals uncertainty,
• whether he tries to "add" facts,
• whether he or she can stick to the sources (e.g. in RAG).
Research shows that Hallucinations are not only a problem of "weaker" models – are also found in the most advanced commercial solutions. This means that "computing power" alone does not solve the quality problem.
Controllable and customizable
Another criterion that cannot be included in a simple ranking is control over the model:
• can it be run locally,
• can it be tuned to your own data,
• whether the method of operation is relatively predictable and repeatable.
For many organizations, these issues are more important than whether the model will generate the most „brilliant” answer.
The model is not everything – the entire pipeline counts„
In practice, users don't work with a "bare model," but with the entire process: input data, knowledge retrieval, response validation, and interface. The same model can perform very differently depending on whether:
• has access to current documents,
• uses semantic search,
• his answers are additionally checked.
Therefore, comparisons like "Bielik vs ChatGPT" only make sense if they take into account specific use case, not the abstract "who is better".
In this context, the rest of the article will focus on specifics: How Bielik performs in Polish language tests and where his approach gives a real advantage over models designed primarily with the global, English-speaking market in mind.
Bielik's results in tests for the Polish language
To talk about Bielik's "form" honestly, it is worth relying on tests that they realistically measure tasks in Polish (classification, QA, text comprehension), not just chat experience. In practice, the most frequently cited benchmark is Open PL LLM Leaderboard (5-shot) which tests NLP competencies in Polish, but does not measure typical conversation/chat.
The hardest results that can be safely quoted:
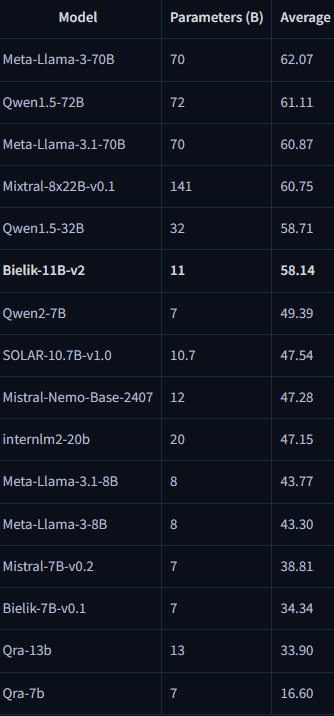
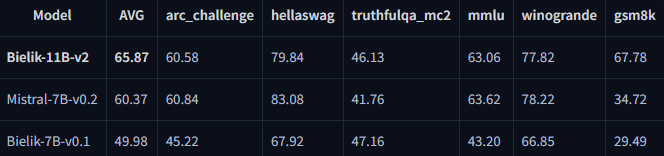
• Bielik-11B-v2 (base) achieves LLM Leaderboard at Open PL average 58.14. For context: in the same table, Mistral-7B-v0.2 has 38.81, and Bielik-7B-v0.1 34.34 – which shows the scale of the qualitative leap in the Bielik family.
• Bielik-11B-v2.x (Instruct) in the technical report it comes out even stronger: e.g. Bielik-11B-v2.3-Instruct = 65.87, and the list includes, among others:. Meta-Llama-3-70B-Instruct = 64.45 (i.e. Bielik is in the very top in this particular PL test).
• Bielik v3 Small (smaller models, but "for Polish use"): in the Open PL LLM Leaderboard base table the report states Bielik-4.5B-v3 = 45.47 and Bielik-1.5B-v3 = 31.48. In the table for manual models: Bielik-1.5B-v3.0-Instruct = 41.36. This is important because it shows that "smaller Bieliks" are being designed as a sensible option where launch costs are a factor.
• Stability after quantization (local implementations): in the Bielik v2 report it can be seen that quantized versions can keep the result very close to full precision – e.g. Bielik-11B-v2.3-Instruct.Q8_0 = 65.76 vs base version 65.71, and even Q6/Q4 still maintain high results. This is practical information for people who want to run the model on "cheaper" hardware.
The conclusion at this stage is simple: in tests strictly for the Polish language, Bielik can be very competitive, and the biggest advantage of the project is that the results go hand in hand with thinking about implementations (including quantization and running locally).
Sources:
https://arxiv.org/html/2505.02550v1
https://arxiv.org/html/2505.02410v2
https://huggingface.co/speakleash/Bielik-11B-v2
Bielik vs ChatGPT/Claude/Gemini in 2026 – differences, fair comparison limits
Comparing Bielik to ChatGPT, Claude, and Gemini can be misleading if we treat them as "the same, just different logo." They are, in practice, different product classes: Bielik is open-weight model, which you can run locally or on your own infrastructure, and ChatGPT/Claude/Gemini is primarily commercial services with the entire ecosystem (applications, tools, integrations, security, support). This doesn't mean that comparisons don't make sense—they do, but you have to compare the right things.
What we know for sure
1) Scale and availability
• Bald Eagle 11B is a model from the SpeakLeash family, published on Hugging Face in variants to run locally (e.g. GGUF to Ollam), under the Apache 2.0 license + additional Terms of Use.
• ChatGPT / Claude / Gemini these are models available mainly as services (applications + API), where some functions depend on the plan and limits.
2) Security and guardrails„
• Bielik's model card states that there are no moderation mechanisms and may generate incorrect or undesirable content – which is important in corporate implementations.
• Commercial services usually have a layer of policies, filters and security tools (this does not guarantee perfection, but changes the risk profile).
3) Price: "you pay differently"„
• Bald Eagle: the model itself does not have a "token pricing" but you pay for infrastructure (GPU/server), maintenance, updates, monitoring and security.
• OpenAI (API) has an official price list per token (depending on the model).
• Anthropic (API) publishes the official price list per token (depending on the model).
• Google Gemini API has an official per-token pricing, with different rates for long prompts (<=200k vs >200k tokens).
For the end user: OpenAI officially communicates ChatGPT subscription tiers (Go $8, Plus $20, Pro $200 per month – local prices may vary).
4) Context and working with large documents
• In the OpenAI API: GPT-4o has 128k of context (according to the model documentation).
• In the Anthropic API: Sonnet 4/4.5 may have 1M context tokens (in practice, access depends on the tier and mode).
• In Gemini API: the official price list distinguishes between requests <=200k and >200k tokens, which confirms support for very long inputs, but "how much exactly max" depends on the model and mode
5) Adoption rate and number of users
There are differences here fundamental and indisputable.
ChatGPT, Claude and Gemini are mass products. ChatGPT is used by hundreds of millions of users per month, Claude, and Gemini operate globally as services embedded in ecosystems (APIs, applications, office tools, search engines). This scale translates to:
• huge amounts of feedback data,
• fast model iterations,
• testing behavior in real, very diverse scenarios
Bald Eagle works on a completely different level of adoption. This is a project:
• niche on a global scale,
• used mainly by the technical community, researchers and companies consciously implementing models locally,
• no mass consumer product of the "app for everyone" type.
This means that The white-tailed eagle does not benefit from economies of scale, which drives the development of commercial models. Fewer users mean:
• less error data in unusual scenarios,
• slower edge-case detection,
• less pressure on conversational quality „for everyone.”.
On the other hand, this smaller scale makes The Bald Eagle is not designed for mass chat, only under specific technical and company applications, where the number of users is not a key metric of success.
Application: in terms of popularity and adoption commercial models absolutely dominate, and trying to put Bielik on the same axis would be unfair. It's just other leagues and other development goals.
| Axis of comparison | Bald Eagle (slef-hosted) | ChatGPT (OpenAI) | Claude (Anthropic) | Gemini (Google) |
|---|---|---|---|---|
| Data and environment control | The most control (for you) | Cloud service | Cloud service | Cloud service |
| Unit cost | No token fees, but infrastructure/maintenance costs | API token fees + in-app plans | API token fees | API token fees |
| Long context | Depends on the implementation and variant (it is more difficult to achieve a uniform standard publicly) | 128k in GPT-4o | up to 1M (Sonnet 4/4.5, conditional) | different thresholds and rates for >200k |
| Security/Filters | No moderation as default layer | Typically built-in service mechanisms | Typically built-in service mechanisms | Typically built-in service mechanisms |
What cannot be honestly determined
„Who is better overall?”
Without a single, common and fresh benchmark performed under the same conditions (the same prompts, the same assessment principles, the same scope of tasks, the same model version), such a slogan is more of a marketing than a scientific one.„"Bald Eagle vs. ChatGPT/Claude/Gemini in Polish corporate tasks"”
It is possible to compare fragmentarily (e.g. PL summaries, emails, classifications), but the results may depend on: prompts, context length, temperature, tools (e.g. web search), and even on whether the model has a system layer and filters.„Direct "price" (cheaper/more expensive)
With Bielik, the cost depends on the infrastructure and load, while with API it depends on the tokens and the model. The same project can be cheaper on a self-hosted platform (high volumes, stable load) or cheaper with an API (low usage, quick startup).„"Quality stability"”
Large services frequently update models and system layers—this can be an advantage (progress), but it makes "once-and-for-all" comparisons difficult. Bielik provides a more predictable version environment, as long as you control it.
If your point of reference is „"the best assistant for everything"” (general knowledge, multimodality, tools, integrations, iteration speed) – ChatGPT/Claude/Gemini usually have the advantage as products-services.
If your point of reference is „"a model under control, possible to install at home, adapted to Polish and company data"” – The white-tailed eagle makes sense as component (engine), not "another app like ChatGPT".
Poland in the world of multilingual AI tests – is the Polish language „winning”?
In 2025, they appeared scientific and independent multilingual benchmarks, which surprised the community: Polish performs as well or even better than English and Chinese in certain AI tasks – even though the latter dominates as training data in most commercial models.
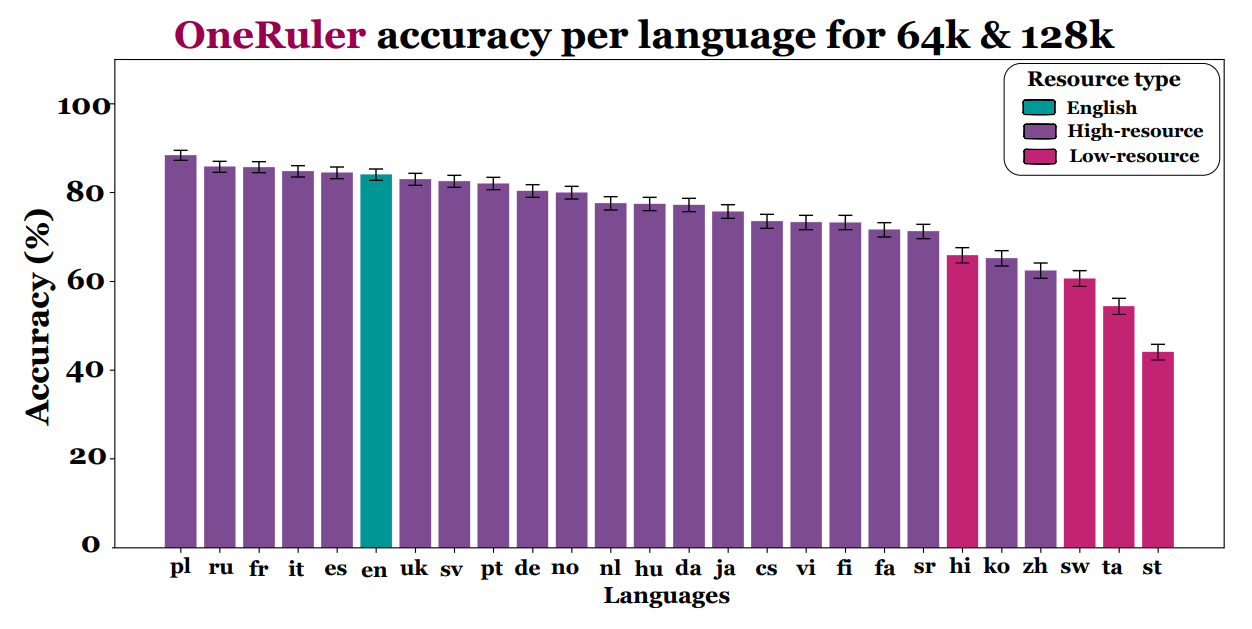
Key findings from analyses comparing the performance of large language models across 26 languages include:
• In tests tasks with a very long context (e.g. sequences of 64 k–128 k tokens), Polish achieved an average accuracy of approx. 88%, which puts him in first place compared to English and Chinese.
• In the same study English was ranked only 6th (approx. 83.9%), and Chinese – much lower.
• According to these analyses, the Polish language was ranked in the top 10 languages at the top, followed by languages such as French, Italian or Spanish.
The authors of this study suggest that the grammatical structure of the Polish language, its morphology and relatively regular rules of inflection can generate strong training signals that help AI models cope with tasks requiring understanding long contexts and precise text analysis.
An important note on interpretation
These studies do not claim that Polish is objectively "„best”"a language for all AI nor that a model trained only in Polish can achieve an advantage over global models. They show that:
• In specific multilingual benchmarks, Polish is very good or the best;
• differences in results between languages are sometimes small and depend on the task and model configuration;
• not all research groups agree that the differences are statistically significant - some scientists emphasize that in tests, Polish does not necessarily "beat" English in all metrics.
What does this mean for Bielik and other models?
For Polish and multilingual models such as Bielik, these results are good news: indicate that Polish has advantages that can be used in designing better AI and benchmarks. This confirms the direction of language specialization and the value of building models capable of deep understanding of languages beyond English.
When Bielik makes the most sense in a company
Bielik is not a "universal assistant for everything" and that is why in certain scenarios has a very specific advantage over commercial models. Works best where it counts. Polish language, data control and predictability of operation, not a set of add-ons known from ready-made chatbots.
Working with company documents in Polish (RAG)
If a company wants to use AI to:
• analysis of contracts, regulations, procedures,
• searching for information in documentation,
• answering employee questions based on internal knowledge,
this Bielik fits well into the RAG architecture (Retrieval-Augmented Generation). Results from Polish benchmarks show that the model can understand complex content in Polish, which in practice means fewer misinterpretations and less "English-language thinking" transferred to the Polish reality.
When data cannot leave the organization
In many companies (law, finance, administration, production) the following are key:
• GDPR,
• trade secret,
• audit or regulatory requirements.
Bielik can be run locally (self-hosted) – without sending data to external APIs. For such organizations, this is often a decisive factor, even if commercial models offer higher "overall" call quality.
Where cost and scalability matter
Using large-scale commercial models on a company scale can be costly and financially difficult to predict. Bielik:
• there is no cost per token,
• allows you to control the infrastructure,
• tolerates quantization well without significant loss of quality.
This makes is a sensible option for larger numbers of users or intensive document processing, where API costs are rising rapidly.
Projects requiring model adaptation
The white-tailed eagle works well where:
• a specific response style is needed,
• consistency of terminology is important,
• the model must operate according to clearly defined rules.
The ability to tune (fine-tuning, system instructions, prompt control) gives companies greater predictability of model behavior than in the case of "black boxes" offered as a service.
In short: Bielik makes the most sense not where you're looking for "the best chat for everything", but where AI is supposed to be working tool – working in Polish, using company data, under the full control of the organization. In the next chapter, it's worth taking an honest look at the other side of the coin: limitations, risks and what still requires caution in 2026.
Yes. Bielik is an open-source model released under licenses that allow commercial use, also in companies. However, it is crucial to check the license specific model version (e.g. v2, v3, Instruct) as details may vary.
Yes. That's one of its greatest advantages. The bald eagle can act locally (self-hosted) – on a company server or dedicated infrastructure – without sending data to external APIs. This makes it easier to meet GDPR and security policy requirements.
Works best in:
• work on Polish documents (RAG),
• analysis of legal texts, regulations, procedures,
• internal company assistants,
• projects requiring full control over data and costs.
Bielik – like any LLM – can:
• make factual errors (hallucinations),
• cannot cope with very specialized knowledge without additional data,
• require an appropriate "environment" (RAG, validation) to operate safely in the company.
This is not a „plug and play” model in the sense of a ready-made chatbot with tools.
May be support, but it should not act as the sole source of decisions. Research shows that No AI model – including commercial ones – can handle high-risk tasks flawlessly. In such applications, Bielik should work in conjunction with source documents and human supervision.
The Bald Eagle in 2026 is no longer an experiment or a curiosity from the "Polish AI" category. mature family of models, which has clearly defined strengths: very good work in Polish, reasonable results in benchmarks, the ability to run locally and real usability in corporate scenarios based on documents and internal knowledge.
Comparisons with ChatGPT, Claude or Gemini show one important thing: the biggest model doesn't always win, and increasingly, the one best suited to a specific language and task. Bielik doesn't compete in the field of multimodal assistants "for everything," but where precision, control, and Polish context matter, it can be a very strong choice.
Looking ahead, Bielik's development direction seems promising. The project consistently improves quality, opens up to standardized evaluations, and responds to real market needs, not just to a competition of parameters. If this trend continues, Polish language models have a chance not only to catch up with the world leaders in their niches, but also to become a reference point for AI designed "locally, but at a global level"„.



