

Polski projekt Bielik AI coraz częściej pojawia się w rozmowach o dużych modelach językowych – nie tylko jako ciekawostka „made in Poland”, ale jako realna alternatywa w konkretnych zastosowaniach. W 2026 roku Bielik ma już kilka dojrzałych wersji, własne benchmarki i rosnące grono wdrożeń, co naturalnie prowokuje pytanie: jak wypada na tle globalnych gigantów pokroju ChatGPT, Claude czy Gemini?
Ten artykuł nie jest ani bezkrytyczną laurką, ani próbą udowodnienia, że „polskie AI jest najlepsze na świecie”. Zamiast tego przyglądamy się faktom – raportom technicznym, wynikom badań i rzeczywistym scenariuszom użycia – aby sprawdzić, gdzie Bielik faktycznie radzi sobie bardzo dobrze, gdzie ma ograniczenia i kiedy jego wybór ma więcej sensu niż sięganie po komercyjne modele zza oceanu.

Co się zmieniło w Bieliku w ostatnich miesiącach
W drugiej połowie 2025 i na przełomie roku (końcówka 2025 – styczeń 2026) wokół Bielika zaszły zmiany, które z „polskiego LLM-a do testów” robią coraz bardziej dojrzałą rodzinę modeli i narzędzi – z jasnym kierunkiem: dobra polszczyzna, rozsądna efektywność i realna użyteczność we wdrożeniach.
Najważniejsze zmiany to:
• Debiut Bielik-11B v3.0 Instruct – publicznie dostępnej wersji instrukcyjnej (Instruct), opisanej jako kolejny krok względem linii v2. W karcie modelu podkreślono m.in. trening z wykorzystaniem zasobów HPC (Athena/Helios) oraz mocny nacisk na jakość wielojęzyczną w Europie (przy utrzymaniu priorytetu dla polskiego).
• Ugruntowanie „małych” Bielików v3 (1.5B i 4.5B) jako pełnoprawnej gałęzi projektu – wraz z technicznym raportem v3 Small. To ważne, bo to nie jest „okrojona wersja dużego modelu”, tylko świadome podejście: lepsza efektywność w polskim dzięki m.in. własnemu tokenizerowi i rozwiązaniom treningowym, które mają podnosić jakość bez pompowania parametrów.
• Lepsza dostępność do uruchamiania lokalnie (self-hosted) – obok publikacji na Hugging Face widać też kanały dystrybucji typowe dla świata „local LLM”, np. paczki pod Ollama (co realnie obniża próg wejścia dla testów na własnym sprzęcie).
• Więcej „zewnętrznej” weryfikacji i presji na standaryzację testów – pojawiają się publiczne zgłoszenia o ewaluację w inicjatywach typu EuroEval (to sygnał, że społeczność chce porównywać modele w ustrukturyzowany sposób, a nie tylko na podstawie wrażeń).
W praktyce oznacza to, że „Bielik w 2026” to już nie jeden model, tylko ekosystem: od wersji małych (tańszych w uruchomieniu), przez średnie/większe warianty instrukcyjne, po coraz bardziej dojrzałe podejście do porównywania wyników i dystrybucji.

Jak w ogóle mierzyć „jak dobry jest model” – kryteria, które mają sens
Porównywanie modeli językowych bardzo łatwo sprowadzić do jednego pytania: który jest najlepszy? Problem w tym, że w praktyce nie istnieje jedna uniwersalna miara „jakości AI”. To, czy dany model jest „dobry”, zależy od tego do czego ma być używany, w jakim języku i w jakich warunkach. Dlatego zanim zestawi się Bielika z globalnymi gigantami, warto uporządkować kryteria, które faktycznie mają znaczenie.
Benchmarki – przydatne, ale nie wystarczające
Benchmarki to zestandaryzowane testy, które sprawdzają m.in. rozumienie tekstu, wnioskowanie czy generowanie odpowiedzi. Są potrzebne, bo pozwalają porównywać modele w podobnych warunkach, ale mają istotne ograniczenia. Często badają wąski zakres umiejętności, bywają podatne na „uczenie się pod test” i rzadko oddają realne warunki pracy, np. z dokumentami firmowymi czy danymi nieustrukturyzowanymi.
Dlatego wysoki wynik w benchmarku nie zawsze oznacza, że model sprawdzi się w codziennym użyciu – zwłaszcza poza językiem angielskim.
Język i kontekst kulturowy
Jednym z najczęściej pomijanych kryteriów jest jakość pracy w konkretnym języku. Modele trenowane głównie na anglojęzycznych danych mogą osiągać świetne wyniki „globalnie”, ale w praktyce gorzej radzić sobie z:
• złożoną fleksją,
• idiomami,
• językiem prawnym lub urzędowym,
• lokalnym kontekstem kulturowym.
W tym sensie model „słabszy” parametrowo, ale trenowany z myślą o danym języku, bywa po prostu bardziej użyteczny w konkretnych zadaniach.
Stabilność odpowiedzi i halucynacje
Coraz większą wagę przykłada się do tego, jak model zachowuje się, gdy nie zna odpowiedzi. Z perspektywy użytkownika biznesowego lub administracyjnego ważne jest nie tylko czy model odpowie, ale jak to zrobi:
• czy jasno sygnalizuje niepewność,
• czy próbuje „dopowiadać” fakty,
• czy potrafi trzymać się źródeł (np. w RAG).
Badania pokazują, że halucynacje nie są problemem wyłącznie „słabszych” modeli – występują również w najbardziej zaawansowanych rozwiązaniach komercyjnych. To sprawia, że sama „moc obliczeniowa” nie rozwiązuje problemu jakości.
Możliwość kontroli i dostosowania
Kolejnym kryterium, którego nie da się ująć w prostym rankingu, jest kontrola nad modelem:
• czy można uruchomić go lokalnie,
• czy da się dostroić go do własnych danych,
• czy sposób działania jest w miarę przewidywalny i powtarzalny.
Dla wielu organizacji te kwestie są ważniejsze niż to, czy model wygeneruje najbardziej „błyskotliwą” odpowiedź.
Model to nie wszystko – liczy się cały „pipeline”
W praktyce użytkownicy nie pracują z „gołym modelem”, ale z całym procesem: danymi wejściowymi, wyszukiwaniem wiedzy, walidacją odpowiedzi i interfejsem. Ten sam model może wypadać bardzo różnie w zależności od tego, czy:
• ma dostęp do aktualnych dokumentów,
• korzysta z wyszukiwania semantycznego,
• jego odpowiedzi są dodatkowo sprawdzane.
Dlatego porównania w stylu „Bielik vs ChatGPT” mają sens tylko wtedy, gdy uwzględniają konkretny scenariusz użycia, a nie abstrakcyjne „kto jest lepszy”.
W tym kontekście dalsza część artykułu skupi się już na konkretach: jak Bielik wypada w testach pod język polski i gdzie jego podejście daje realną przewagę nad modelami projektowanymi głównie z myślą o globalnym, anglojęzycznym rynku.
Wyniki Bielika w testach pod język polski
Żeby mówić o „formie” Bielika uczciwie, warto oprzeć się na testach, które realnie mierzą zadania po polsku (klasyfikacja, QA, rozumienie tekstu), a nie tylko wrażenia z czatu. W praktyce najczęściej cytowanym punktem odniesienia jest Open PL LLM Leaderboard (5-shot), który testuje kompetencje NLP po polsku, ale nie mierzy typowej rozmowy/chatowania.
Najbardziej „twarde” wyniki, które da się bezpiecznie zacytować:
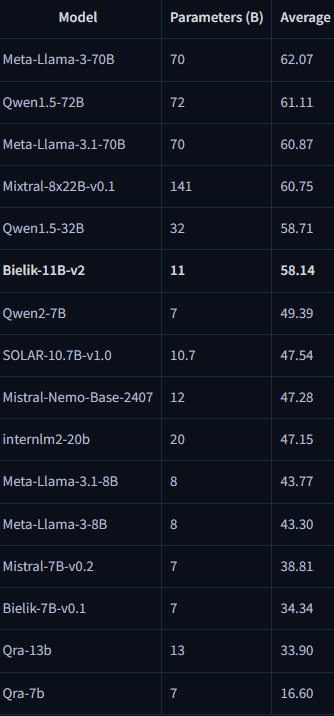
• Bielik-11B-v2 (base) osiąga na Open PL LLM Leaderboard średnio 58.14. Dla kontekstu: w tej samej tabeli Mistral-7B-v0.2 ma 38.81, a Bielik-7B-v0.1 34.34 – co pokazuje skalę skoku jakościowego w rodzinie Bielika.
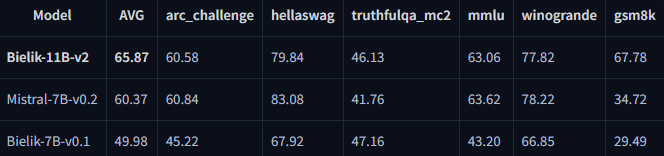
• Bielik-11B-v2.x (Instruct) w raporcie technicznym wypada jeszcze mocniej: np. Bielik-11B-v2.3-Instruct = 65.87, a w zestawieniu obok pojawia się m.in. Meta-Llama-3-70B-Instruct = 64.45 (czyli Bielik plasuje się w ścisłej czołówce w tym konkretnym teście PL).
• Bielik v3 Small (mniejsze modele, ale „pod polski”): w tabeli bazowej Open PL LLM Leaderboard raport podaje Bielik-4.5B-v3 = 45.47 oraz Bielik-1.5B-v3 = 31.48. W tabeli dla modeli instrukcyjnych: Bielik-1.5B-v3.0-Instruct = 41.36. To ważne, bo pokazuje, że „mniejsze Bieliki” są projektowane jako sensowna opcja tam, gdzie liczy się koszt uruchomienia.
• Stabilność po kwantyzacji (wdrożenia lokalne): w raporcie Bielika v2 widać, że wersje skwantyzowane potrafią trzymać wynik bardzo blisko pełnej precyzji – np. Bielik-11B-v2.3-Instruct.Q8_0 = 65.76 vs wersja bazowa 65.71, a nawet Q6/Q4 nadal utrzymują wysokie rezultaty. To praktyczna informacja dla osób, które chcą uruchamiać model na „tańszym” sprzęcie.
Wniosek na tym etapie jest prosty: w testach stricte pod język polski Bielik potrafi być bardzo konkurencyjny, a największą przewagą projektu jest to, że wyniki idą w parze z myśleniem o wdrożeniach (w tym kwantyzacji i uruchamianiu lokalnie).
Źródła:
https://arxiv.org/html/2505.02550v1
https://arxiv.org/html/2505.02410v2
https://huggingface.co/speakleash/Bielik-11B-v2
Bielik vs ChatGPT/Claude/Gemini w 2026 – różnice, uczciwe granice porównania
Porównywanie Bielika do ChatGPT, Claude i Gemini bywa mylące, jeśli traktujemy je jak „to samo, tylko inne logo”. To w praktyce różne klasy produktów: Bielik jest modelem open-weight, który możesz uruchamiać lokalnie lub na własnej infrastrukturze, a ChatGPT/Claude/Gemini to przede wszystkim komercyjne usługi z całym ekosystemem (aplikacje, narzędzia, integracje, bezpieczeństwo, wsparcie). To nie znaczy, że porównanie nie ma sensu – ma, tylko trzeba porównywać właściwe rzeczy.
Co wiemy na pewno
1) Skala i dostępność
• Bielik 11B to model z rodziny SpeakLeash, publikowany na Hugging Face w wariantach do uruchomienia lokalnie (np. GGUF do Ollama), na licencji Apache 2.0 + dodatkowe Terms of Use.
• ChatGPT / Claude / Gemini to modele dostępne głównie jako usługi (aplikacje + API), gdzie część funkcji zależy od planu i limitów.
2) Bezpieczeństwo i „guardrails”
• Wprost w model card Bielika jest informacja, że nie ma mechanizmów moderacji i może generować treści błędne lub niepożądane – co jest istotne w firmowych wdrożeniach.
• Komercyjne usługi zwykle mają warstwę polityk, filtrów i narzędzi bezpieczeństwa (to nie gwarantuje perfekcji, ale zmienia profil ryzyka).
3) Cena: „płacisz inaczej”
• Bielik: sam model nie ma „cennika za token”, ale płacisz za infrastrukturę (GPU/serwer), utrzymanie, aktualizacje, monitoring i bezpieczeństwo.
• OpenAI (API) ma oficjalny cennik per token (zależny od modelu).
• Anthropic (API) publikuje oficjalny cennik per token (zależny od modelu).
• Google Gemini API ma oficjalny cennik per token, z innymi stawkami dla długich promptów (<=200k vs >200k tokenów).
Dla użytkownika końcowego: OpenAI oficjalnie komunikuje progi subskrypcji ChatGPT (Go 8 USD, Plus 20 USD, Pro 200 USD miesięcznie – ceny lokalne mogą się różnić).
4) Kontekst i praca na dużych dokumentach
• W API OpenAI: GPT-4o ma 128k kontekstu (wg dokumentacji modelu).
• W API Anthropic: Sonnet 4/4.5 może mieć 1M tokenów kontekstu (w praktyce dostęp zależy od tieru i trybu).
• W Gemini API: oficjalny cennik rozróżnia zapytania <=200k i >200k tokenów, co potwierdza obsługę bardzo długich wejść, ale „ile dokładnie max” zależy od modelu i trybu
5) Skala adopcji i liczba użytkowników
Tu różnice są fundamentalne i niepodlegające dyskusji.
ChatGPT, Claude i Gemini to produkty masowe. ChatGPT jest używany przez setki milionów użytkowników miesięcznie, Claude i Gemini działają globalnie jako usługi wbudowane w ekosystemy (API, aplikacje, narzędzia biurowe, wyszukiwarki). Ta skala przekłada się na:
• ogromne ilości danych zwrotnych,
• szybkie iteracje modeli,
• testowanie zachowań w realnych, bardzo zróżnicowanych scenariuszach
Bielik działa na zupełnie innym poziomie adopcji. To projekt:
• niszowy w skali globalnej,
• używany głównie przez społeczność techniczną, badaczy i firmy świadomie wdrażające modele lokalnie,
• bez masowego produktu konsumenckiego typu „aplikacja dla każdego”.
To oznacza, że Bielik nie korzysta z efektu skali, który napędza rozwój modeli komercyjnych. Mniej użytkowników to:
• mniej danych o błędach w nietypowych scenariuszach,
• wolniejsze wykrywanie edge-case’ów,
• mniejsza presja na jakość konwersacyjną „dla każdego”.
Z drugiej strony – ta mniejsza skala sprawia, że Bielik nie jest projektowany pod masowy czat, tylko pod konkretne zastosowania techniczne i firmowe, gdzie liczba użytkowników nie jest kluczową metryką sukcesu.
Wniosek: pod względem popularności i adopcji modele komercyjne absolutnie dominują, a próba stawiania Bielika na tej samej osi byłaby nieuczciwa. To po prostu inne ligi i inne cele rozwoju.
| Oś porównania | Bielik (slef-hosted) | ChatGPT (OpenAI) | Claude (Anthropic) | Gemini (Google) |
|---|---|---|---|---|
| Kontrola danych i środowiska | Największa kontrola (u Ciebie) | Usługa chmurowa | Usługa chmurowa | Usługa chmurowa |
| Koszt jednostkowy | Brak opłat za token, ale koszt infrastruktury/utrzymania | Opłaty za token w API + plany w aplikacji | Opłaty za token w API | Opłaty za token w API |
| Długi kontekst | Zależy od wdrożenia i wariantu (publicznie trudniej o jednolity standard) | 128k w GPT-4o | do 1M (Sonnet 4/4.5, warunkowo) | różne progi i stawki dla >200k |
| Bezpieczeństwo/filtry | Brak moderacji jako domyślnej warstw | Zwykle wbudowane mechanizmy usługowe | Zwykle wbudowane mechanizmy usługowe | Zwykle wbudowane mechanizmy usługowe |
Czego nie da się uczciwie przesądzić
„Kto jest lepszy ogólnie?”
Bez jednego, wspólnego i świeżego benchmarku robionego w tych samych warunkach (te same prompty, te same zasady oceny, ten sam zakres zadań, ta sama wersja modeli) takie hasło jest bardziej marketingowe niż naukowe.„Bielik vs ChatGPT/Claude/Gemini w polskich zadaniach firmowych”
Da się porównać fragmentarycznie (np. streszczenia PL, maile, klasyfikacje), ale wyniki potrafią zależeć od: promptów, długości kontekstu, temperatury, narzędzi (np. wyszukiwanie w sieci), a nawet od tego, czy model ma warstwę systemową i filtry.„Cena” wprost (taniej/drożej)
Przy Bieliku koszt zależy od infrastruktury i obciążenia, przy API zależy od tokenów i modelu. Ten sam projekt może być tańszy na self-host (duże wolumeny, stabilne obciążenie), albo tańszy w API (małe użycie, szybkie uruchomienie).„Stabilność jakości”
Duże usługi często aktualizują modele i warstwy systemowe – to bywa zaletą (postęp), ale utrudnia porównania „raz na zawsze”. Bielik daje bardziej przewidywalne środowisko wersji, o ile Ty je kontrolujesz.
Jeśli Twoim punktem odniesienia jest „najlepszy asystent do wszystkiego” (wiedza ogólna, multimodalność, narzędzia, integracje, szybkość iteracji) – ChatGPT/Claude/Gemini zwykle mają przewagę jako produkty-usługi.
Jeśli Twoim punktem odniesienia jest „model pod kontrolą, możliwy do postawienia u siebie, dopasowany do polskiego i firmowych danych” – Bielik ma sens jako komponent (silnik), a nie „kolejna aplikacja jak ChatGPT”.
Polska w świecie wielojęzycznych testów AI – czy język polski „wygrywa”?
W 2025 roku pojawiły się naukowe i niezależne benchmarki wielojęzyczne, które zaskoczyły środowisko: język polski w pewnych zadaniach AI wypada równie dobrze lub nawet lepiej niż angielski i chiński – mimo że te ostatnie dominują jako dane treningowe w większości komercyjnych modeli.
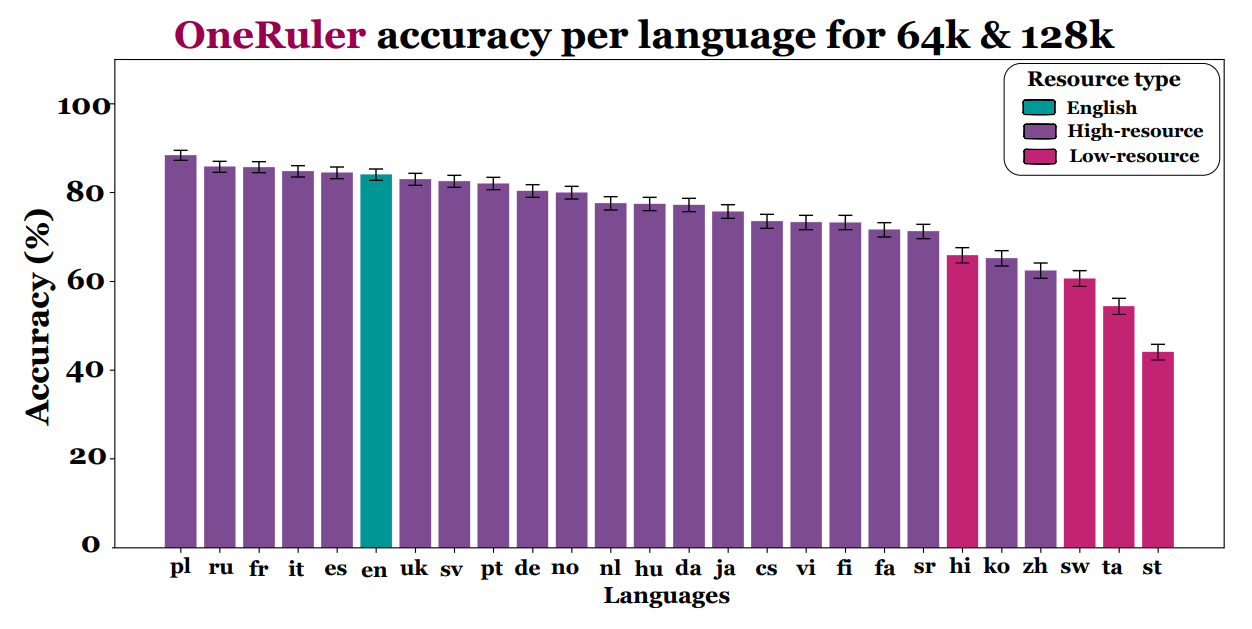
Kluczowe ustalenia z analiz porównujących wydajność dużych modeli językowych w 26 językach to:
• W testach zadaniach z bardzo długim kontekstem (np. sekwencje 64 k–128 k tokenów), polski osiągał średnią dokładność na poziomie ok. 88%, co stawia go na pierwszym miejscu w porównaniu z angielskim i chińskim.
• W tym samym badaniu angielski uplasował się dopiero na 6. miejscu (ok. 83,9%), a chiński – znacznie niżej.
• Ranking top-10 języków według tych analiz umieszczał język polski na szczycie, a następnie języki takie jak francuski, włoski czy hiszpański.
Autorzy tych badań sugerują, że struktura gramatyczna polszczyzny, jej morfologia i względnie regularne zasady fleksji mogą generować silne sygnały treningowe, które pomagają modelom AI radzić sobie w zadaniach wymagających rozumienia długich kontekstów i precyzyjnej analizy tekstu.
Ważna uwaga o interpretacji
Badania te nie twierdzą, że polski jest obiektywnie „najlepszy” język dla wszystkich AI ani że modelem trenowanym tylko po polsku można osiągnąć przewagę nad modelami ogólnoświatowymi. One pokazują, że:
• w konkretnych benchmarkach wielojęzycznych, polski wypada bardzo dobrze lub najlepiej;
• różnice w wynikach między językami bywają niewielkie i zależą od zadania oraz konfiguracji modeli;
• nie wszystkie grupy badawcze zgadzają się, że różnice są statystycznie znaczące — część naukowców podkreśla, że w testach polski niekoniecznie „bije” angielski we wszystkich metrykach.
Co to oznacza dla Bielika i innych modeli
Dla polskich i wielojęzycznych modeli, takich jak Bielik, wyniki te są dobrą wiadomością: wskazują, że język polski ma atuty, które mogą być wykorzystane w projektowaniu lepszych AI i benchmarków. To potwierdza kierunek specjalizacji językowej i wartość budowania modeli zdolnych do głębokiego rozumienia języków poza angielskim.
Kiedy Bielik ma największy sens w firmie
Bielik nie jest „uniwersalnym asystentem do wszystkiego” i właśnie dlatego w określonych scenariuszach ma bardzo konkretną przewagę nad modelami komercyjnymi. Najlepiej sprawdza się tam, gdzie liczy się język polski, kontrola nad danymi i przewidywalność działania, a nie zestaw dodatków znanych z gotowych chatbotów.
Praca na dokumentach firmowych po polsku (RAG)
Jeśli firma chce używać AI do:
• analizy umów, regulaminów, procedur,
• wyszukiwania informacji w dokumentacji,
• odpowiadania na pytania pracowników na podstawie wewnętrznej wiedzy,
to Bielik dobrze wpisuje się w architekturę RAG (Retrieval-Augmented Generation). Wyniki z polskich benchmarków pokazują, że model radzi sobie z rozumieniem złożonych treści w języku polskim, co w praktyce oznacza mniej błędnych interpretacji i mniej „anglojęzycznego myślenia” przenoszonego na polskie realia.
Gdy dane nie mogą opuszczać organizacji
W wielu firmach (prawo, finanse, administracja, produkcja) kluczowe są:
• RODO,
• tajemnica handlowa,
• wymogi audytowe lub regulacyjne.
Bielika można uruchomić lokalnie (self-hosted) – bez wysyłania danych do zewnętrznych API. Dla takich organizacji to często czynnik decydujący, nawet jeśli modele komercyjne oferują wyższą „ogólną” jakość rozmowy.
Tam, gdzie liczy się koszt i skalowalność
Korzystanie z dużych modeli komercyjnych w skali firmy bywa kosztowne i trudne do przewidzenia finansowo. Bielik:
• nie ma kosztu „za token”,
• pozwala kontrolować infrastrukturę,
• dobrze znosi kwantyzację bez dużej utraty jakości.
To sprawia, że jest sensowną opcją przy większej liczbie użytkowników lub intensywnym przetwarzaniu dokumentów, gdzie koszty API szybko rosną.
Projekty wymagające dostosowania modelu
Bielik sprawdza się tam, gdzie:
• potrzebny jest określony styl odpowiedzi,
• ważna jest spójność terminologii,
• model ma działać według jasno zdefiniowanych reguł.
Możliwość dostrajania (fine-tuning, instrukcje systemowe, kontrola promptów) daje firmom większą przewidywalność zachowania modelu niż w przypadku „czarnych skrzynek” oferowanych jako usługa.
W skrócie: Bielik ma największy sens nie tam, gdzie szuka się „najlepszego czatu do wszystkiego”, ale tam, gdzie AI ma być narzędziem roboczym – pracującym po polsku, na firmowych danych, pod pełną kontrolą organizacji. W kolejnym rozdziale warto więc uczciwie przyjrzeć się drugiej stronie medalu: ograniczeniom, ryzykom i temu, co w 2026 roku nadal wymaga ostrożności.
Tak. Bielik jest modelem open-source udostępnianym na licencjach pozwalających na użycie komercyjne, również w firmach. Kluczowe jest jednak sprawdzenie licencji konkretnej wersji modelu (np. v2, v3, Instruct), ponieważ szczegóły mogą się różnić.
Tak. To jedna z jego największych zalet. Bielik może działać lokalnie (self-hosted) – na serwerze firmowym lub dedykowanej infrastrukturze – bez wysyłania danych do zewnętrznych API. Dzięki temu łatwiej spełnić wymagania RODO i polityki bezpieczeństwa.
Najlepiej sprawdza się w:
• pracy na polskich dokumentach (RAG),
• analizie tekstów prawniczych, regulaminów, procedur,
• wewnętrznych asystentach firmowych,
• projektach wymagających pełnej kontroli nad danymi i kosztami.
Bielik – jak każdy LLM – może:
• popełniać błędy faktograficzne (halucynacje),
• nie radzić sobie z bardzo specjalistyczną wiedzą bez dodatkowych danych,
• wymagać odpowiedniego „otoczenia” (RAG, walidacja), by działać bezpiecznie w firmie.
Nie jest to model „plug and play” w sensie gotowego chatbota z narzędziami.
Może być wsparciem, ale nie powinien działać jako jedyne źródło decyzji. Badania pokazują, że żaden model AI – także komercyjny – nie radzi sobie bezbłędnie w zadaniach wysokiego ryzyka. W takich zastosowaniach Bielik powinien działać w połączeniu z dokumentami źródłowymi i nadzorem człowieka.
Bielik w 2026 roku nie jest już eksperymentem ani ciekawostką z kategorii „polskie AI”. To dojrzała rodzina modeli, która ma jasno określone mocne strony: bardzo dobrą pracę w języku polskim, sensowne wyniki w benchmarkach, możliwość uruchamiania lokalnie i realną użyteczność w firmowych scenariuszach opartych o dokumenty i wiedzę wewnętrzną.
Porównania z ChatGPT, Claude czy Gemini pokazują jedną ważną rzecz: nie zawsze wygrywa największy model, a coraz częściej ten najlepiej dopasowany do konkretnego języka i zadania. Bielik nie konkuruje na polu multimodalnych asystentów „do wszystkiego”, ale tam, gdzie liczy się precyzja, kontrola i polski kontekst, potrafi być bardzo mocnym wyborem.
Patrząc w przyszłość, kierunek rozwoju Bielika wydaje się obiecujący. Projekt konsekwentnie poprawia jakość, otwiera się na standaryzowane ewaluacje i odpowiada na realne potrzeby rynku, a nie wyłącznie na wyścig parametrów. Jeśli ten trend się utrzyma, polskie modele językowe mają szansę nie tylko dogonić światową czołówkę w swoich niszach, ale stać się punktem odniesienia dla AI projektowanego „lokalnie, ale na światowym poziomie”.



